There are some new announcements from Brocade and Emulex, which will help to build virtual IT infrastructure with less cables and host adapters.
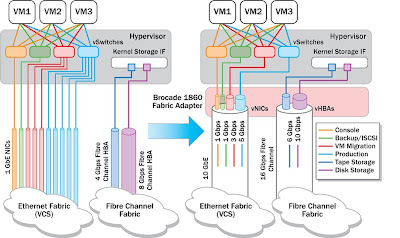
Brocade announced 1860 Fabric Adapter that meets all Fibre Channel and Ethernet connectivity needs in cloud-enabled data centers:
Each port on the Brocade 1860 can be configured in any of the following modes:
HBA mode: Appears as a FC HBA to the OS. It supports 16/8/4 Gbps FC when using a 16 Gbps SFP+ and 8/4/2 Gbps when using an 8 Gbps SFP+. In FC mode N_Port trunking can aggregate two 16 Gbps Fibre Channel links into a single logical 32 Gbps link with frame-level load-balancing for the highest levels of link utilization and transparent, automatic failover and failback for high availability.
NIC mode: Appears as a 10 GbE NIC to the OS. It supports 10 GbE with DCB, iSCSI, and TCP/IP simultaneously.
CNA mode: Appears as two independent devices, a Fibre Channel HBA (using FCoE) and a 10 GbE NIC to the OS. It supports 10 GbE with DCB, FCoE, iSCSI, and TCP/IP simultaneously.
Brocade vFLink technology allows a single Brocade 1860 Fabric Adapter to logically partition a physical link into as many as eight virtual fabric links (vFlinks) per port. This is achieved by replicating the adapter at the PCIe bus level and presenting multiple PCIe physical functions (PFs) to the OS layer. The OS not need to have any special support for vFLink; it will just see each vNIC or vHBA as a separate physical I/O device, and it will know how to operate it as long as the appropriate driver is present. When configured as 16 Gbps Fibre Channel, a single physical port can support up to eight vHBAs. When configured as 10 GbE, a physical port can support any combination of up to eight vNICs and vHBAs. In this case, vHBAs are achieved by using FCoE protocol.
Direct I/O removes the hypervisor involvement in I/O processing and enables near-native performance for those VMs. However, directly assigned I/O devices cannot be accessed by more than one VM at a time, thus requiring dedicated hardware resources. I/O virtualization technologies like vFLink can help alleviate this problem by logically partitioning the adapter and directly mapping vNICs or vHBAs to VMs, enabling a better sharing of physical adapters with direct I/O.
Single-Root I/O Virtualization (SR-IOV) allows a PCIe device to be virtualized, by introducing the concept of PCI virtual functions (VFs) - lightweight PCI functions that can be used only to move data in and out of the device, and that have a minimum set of configuration resources. VFs can be directly mapped to virtual machines using direct I/O technology, while the hypervisor retains control of the PF, which requires what is called a “split-driver” model.
By implementing Virtual Machine Optimized Ports (VMOPs), the Brocade 1860 leverages hypervisor multi-queue technologies such as VMware NetQueue and Microsoft VMQ to offload the incoming network packet classification and sorting tasks from the hypervisor onto the adapter, freeing the CPU and enabling line-rate performance.
Virtual Ethernet Bridge (VEB) inside the I/O adapter offloads Inter-VM traffic switching. The adapter is responsible for providing both inter-VM and inbound/outbound communication. Packets are switched directly in the adapter with no hypervisor involvement, providing high performance, low latency and low CPU utilization. No special support is required from the access layer switch, since inter-VM traffic continues to be switched inside the server.
Virtual Ethernet Port Aggregator (VEPA) extends network connectivity all the way to the applications, making VMs appear as if they were directly connected to the physical access layer switch. All VM-generated traffic is sent out of the adapter to an external switch, essentially moving the demarcation point of the network back to the physical access layer. The external switch can then apply filtering and forwarding rules to the VM traffic, and it can also account for and monitor the traffic with the same management tools that network administrators are accustomed to.
Multi-channel VEPA is an additional enhancement to VEPA to allow a single Ethernet connection to be divided into multiple independent channels, where each channel acts as a unique connection to the network. The benefit of multi-channel VEPA is that it allows a combination of VEPA for VMs where strict network policy enforcement and traffic monitoring is important, and hardware-based VEB for high-performance VMs where minimal latency and maximum throughput is a requirement.
Edge Virtual Bridging (EVB) defines the standard for VEPA and the Virtual Station Interface Discovery Protocol (VDP)—sometimes referred to as Automatic Migration of Port Profiles (AMPP)—that can be used to automatically associate and de-associate a VM to a set of network policies, sometimes referred to as “port profile.”
In traditional virtualized environments, management of physical and virtual networking is fragmented, as the software vSwitch is typically managed by the server administrator, whereas the physical network is managed by the network administrator. The network administrator has no visibility into the software switch management, and is unable to enforce networking policies on inter-VM traffic within a physical host. By offloading the switching from the hypervisor onto the adapter or the access layer switch, management of physical and virtual switching can be unified under a single management application by the network administrator.
Emulex also announced XE201 I/O controller (only controller, not host adapter!), which provides a combination of up to four ports of native 8 and 16Gb/s FC, FCoE, iSCSI, RDMA over Converged Ethernet (RoCE), 10 and 40Gb/s Ethernet. XE201 supports a wide range of new features for both server initiator and storage target modes, including:
End-to-end data integrity with BlockGuard™ offload eliminates silent data corruption as data traverses the system from the O/S all the way to the disk array.
vScale™ workload-based performance and scalability—multi-core ASIC engine with eight cores, running a combination of standard protocols and specialized functions
vScale resource pooling—dynamically allocates resources to multiple protocols, enabling scale-up of up to 256 VMs (255 virtual functions [VF] + 1 physical function [PF]), 2000 simultaneous TCP/IP sessions
vEngine™—I/O offload lowers CPU burden on host server, enabling support for more VMs
vPath™ virtual I/O capability supports emerging I/O virtualization standards including Single Root I/O Virtualization (SR-IOV), Virtual Ethernet Port Aggregator (VEPA) and Virtual Ethernet Bridge (VEB), all of which are supported by an internal Emulex Ethernet switch that allows data to be forwarded between VMs, which are collocated on same server, without travelling to an external switch for higher performance and ensuring traffic isolation
And what will Qlogic answer?






